Data Wrangling
User-defined rules, natively compiled, executing against in-memory datasets for unrivalled performance in real-time data wrangling.

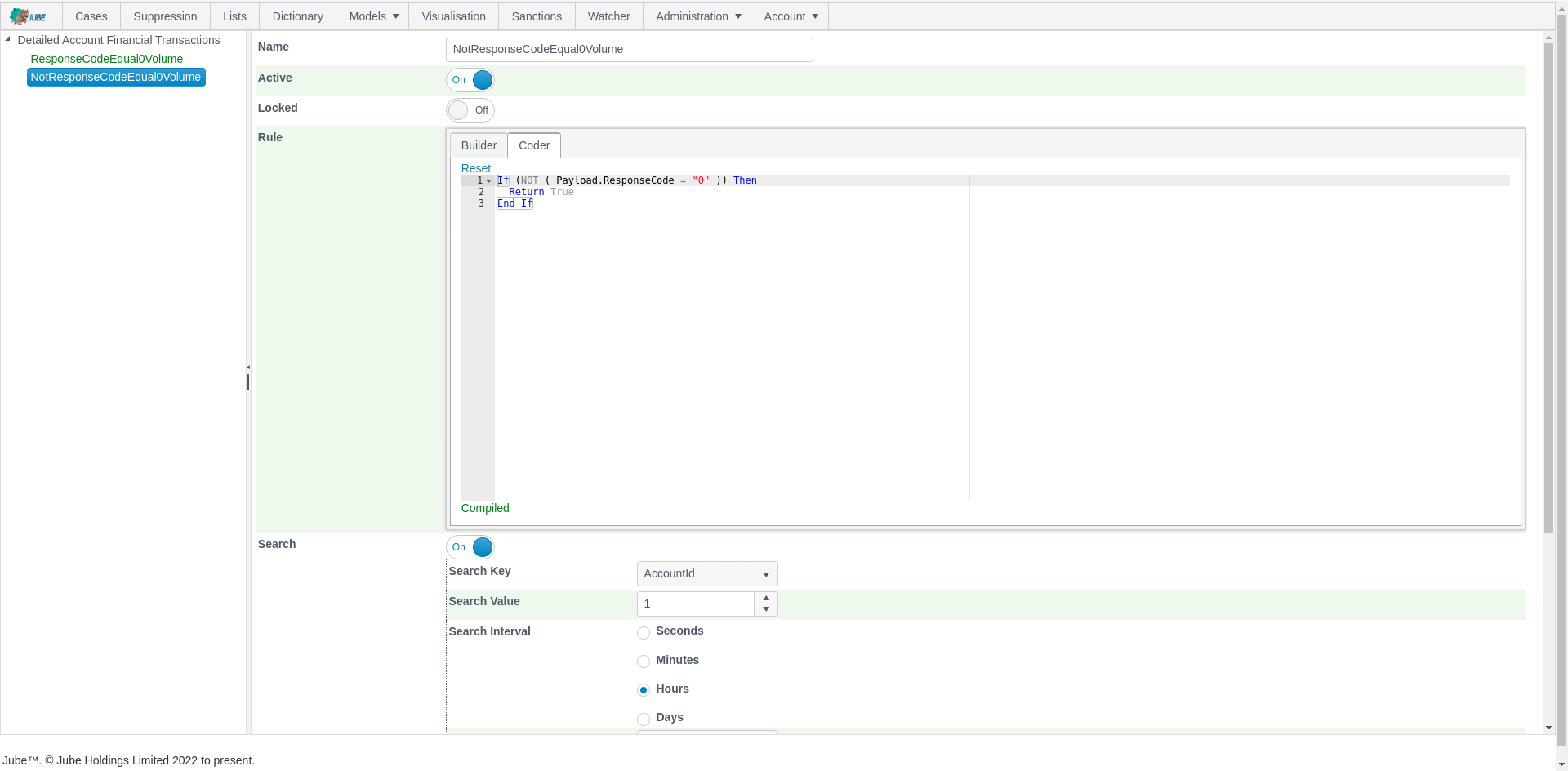
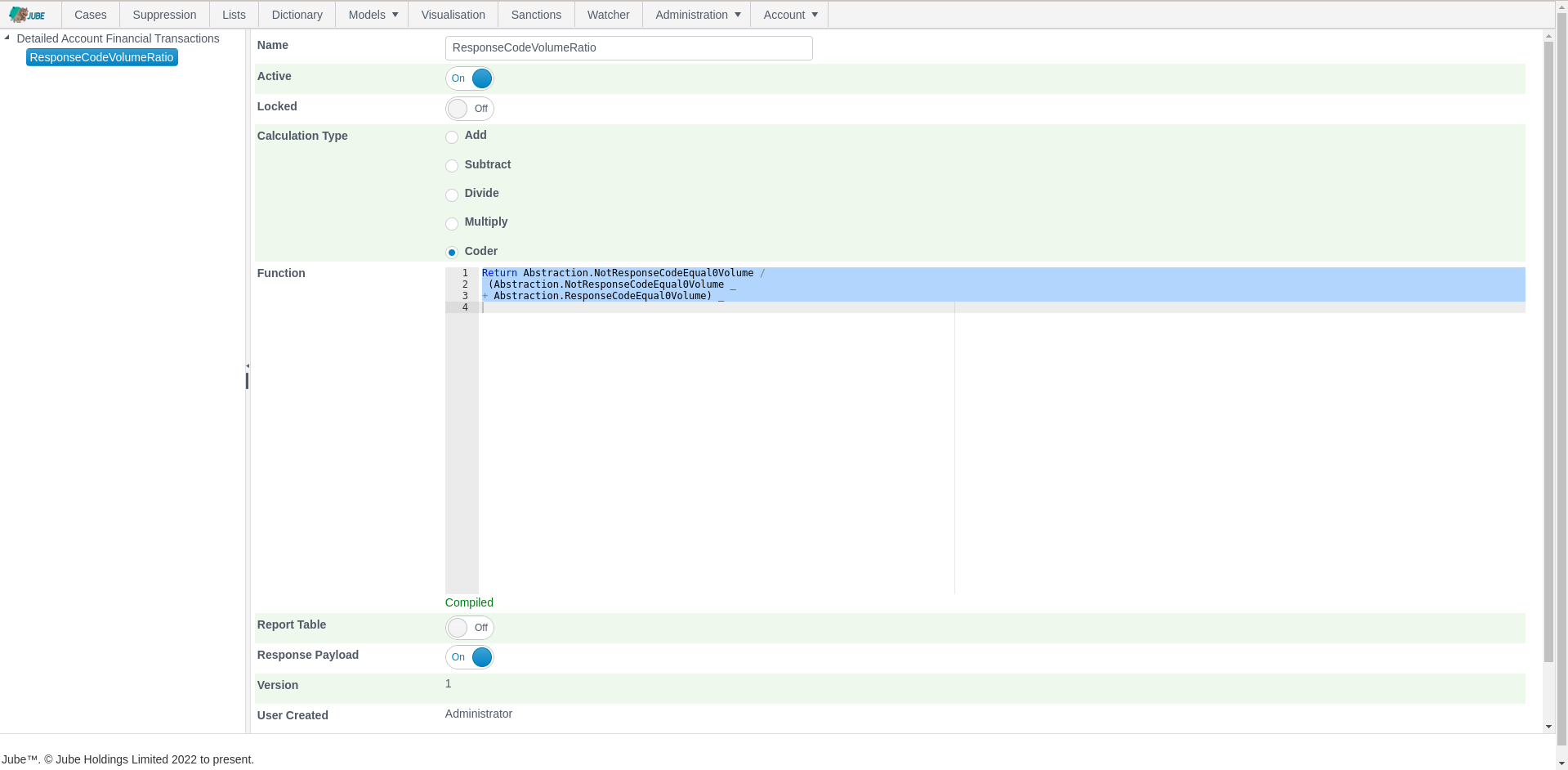
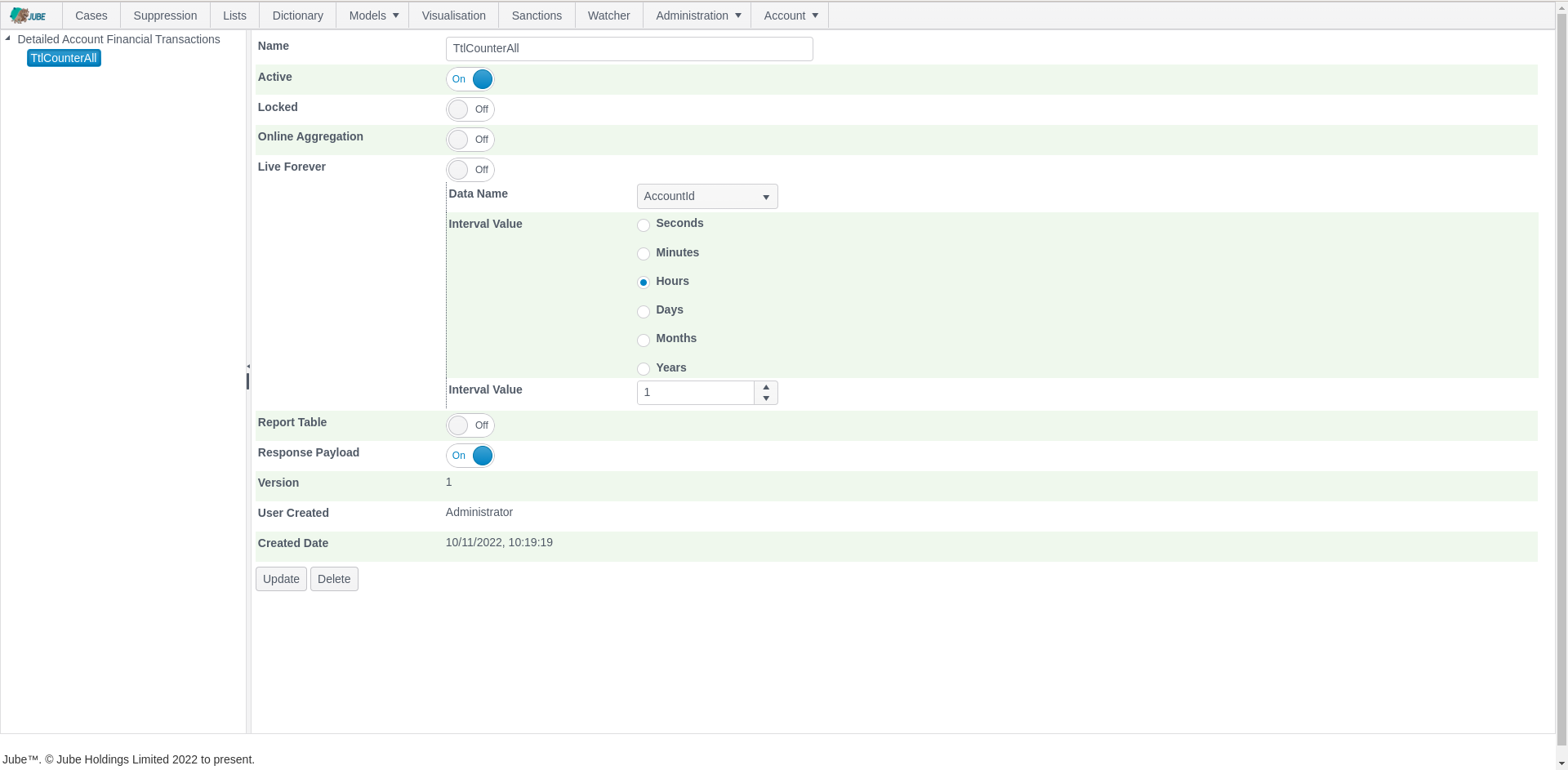
Data wrangling is real-time. Data wrangling is directed via a series of rules created using either a point-and-click rule builder or an intuitive rule coder. Rules are in-memory matching functions tested against data returned from high-performance cache tables, where datasets are fetched only once for each key that the rules roll up to for each transaction or event processing, with the matches aggregating using a variety of functions. Alternative means of maintaining a lightweight long-term state to facilitate data wrangling is Time To Live (TTL) Counters which are incremented on rule match and then decremented for that incrementation on time-lapse.
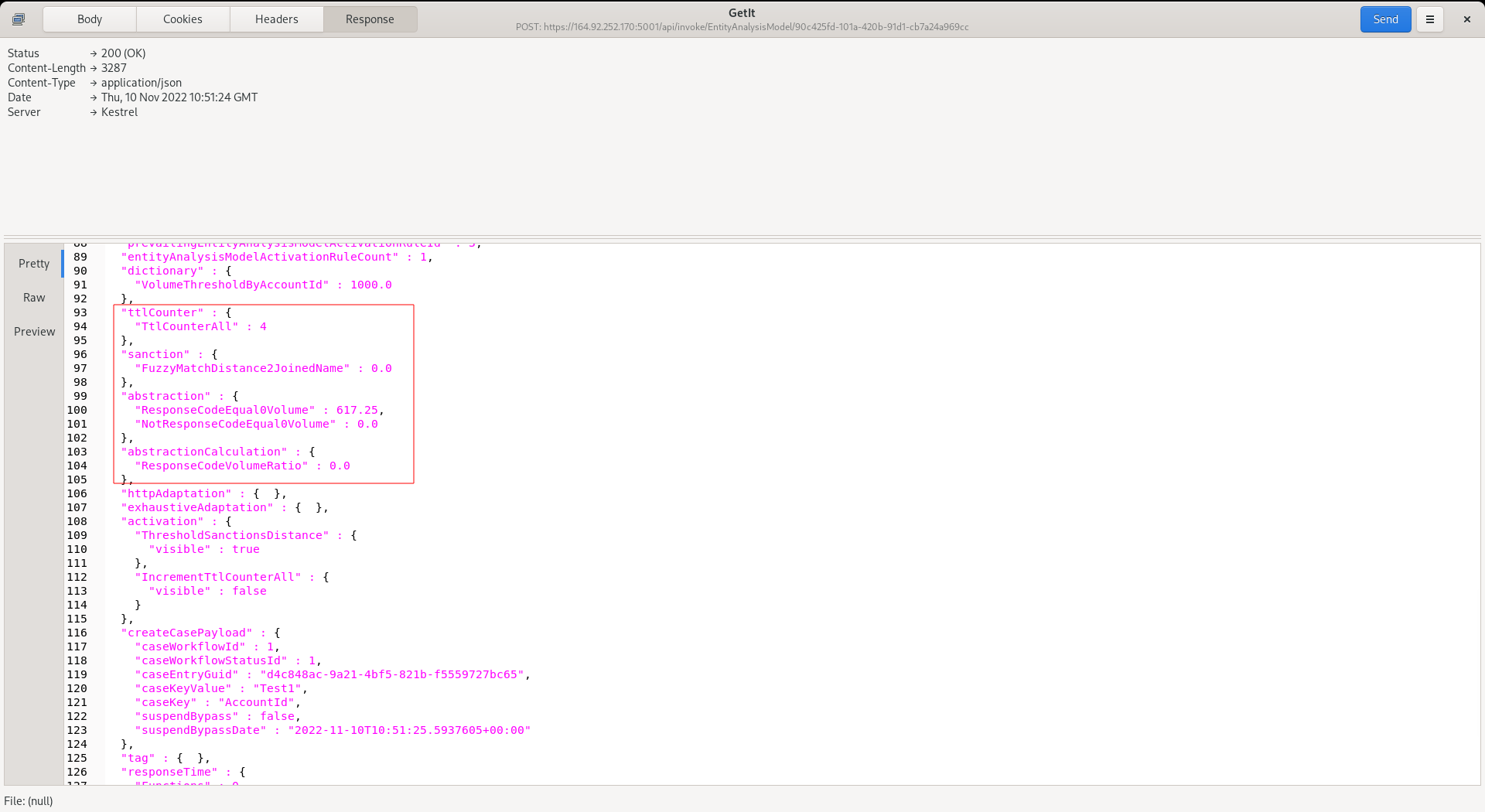
Data wrangling return values are independently available for use as features in artificial intelligence training and real-time recall or tested by rules to perform a specific action (e.g., the rejection of a transaction or event). Wrangled values are returned in the real-time response payload and can facilitate a Function as a Service (FaaS) pattern. Response payload data is also stored in an addressable fashion, improving the experience of advanced analytical reporting while also reducing database resource \ compute cost.
Jube is developed statelessly and can support massive horizontal scalability and separation of concerns in the infrastructure.
